Abstract
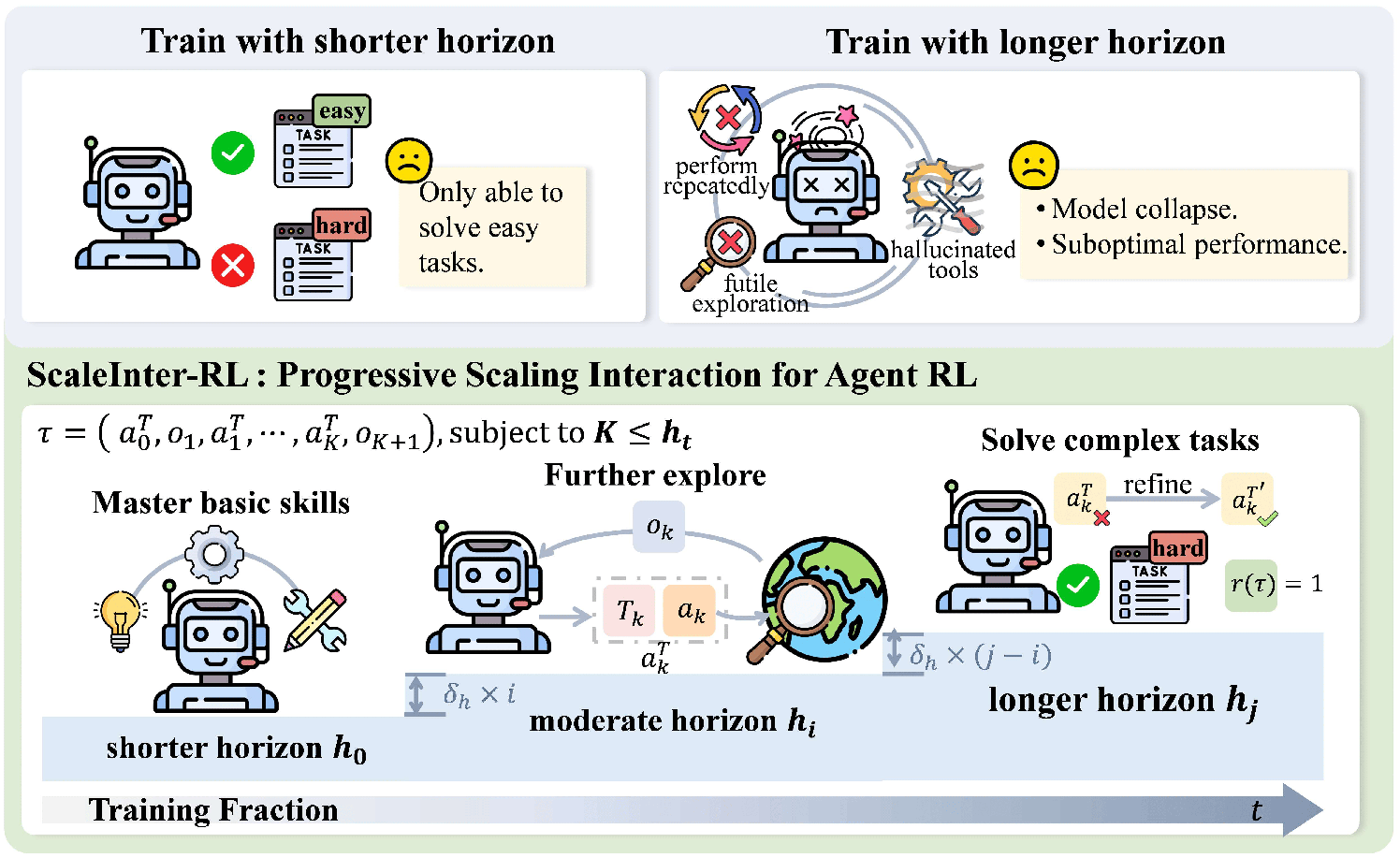
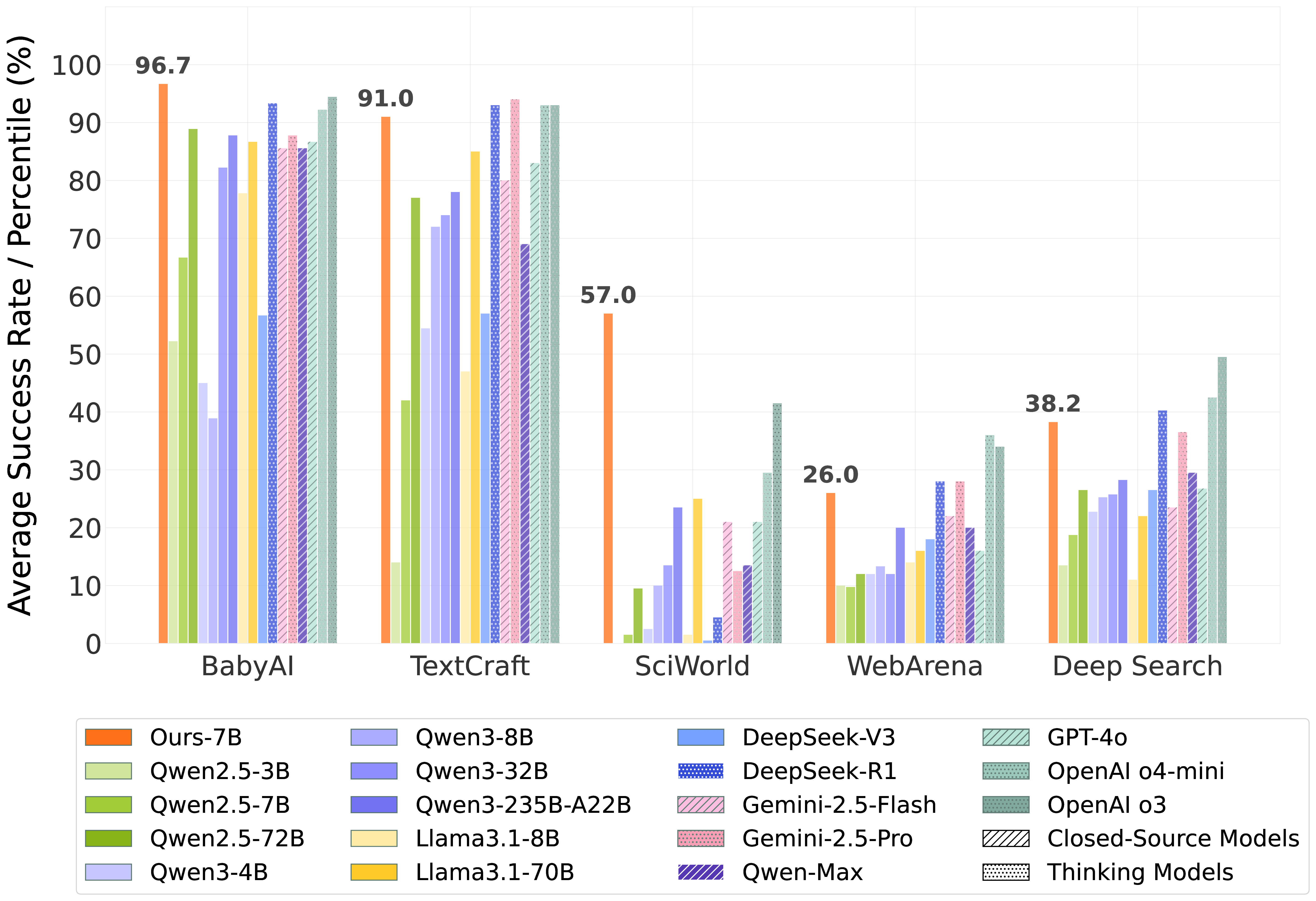
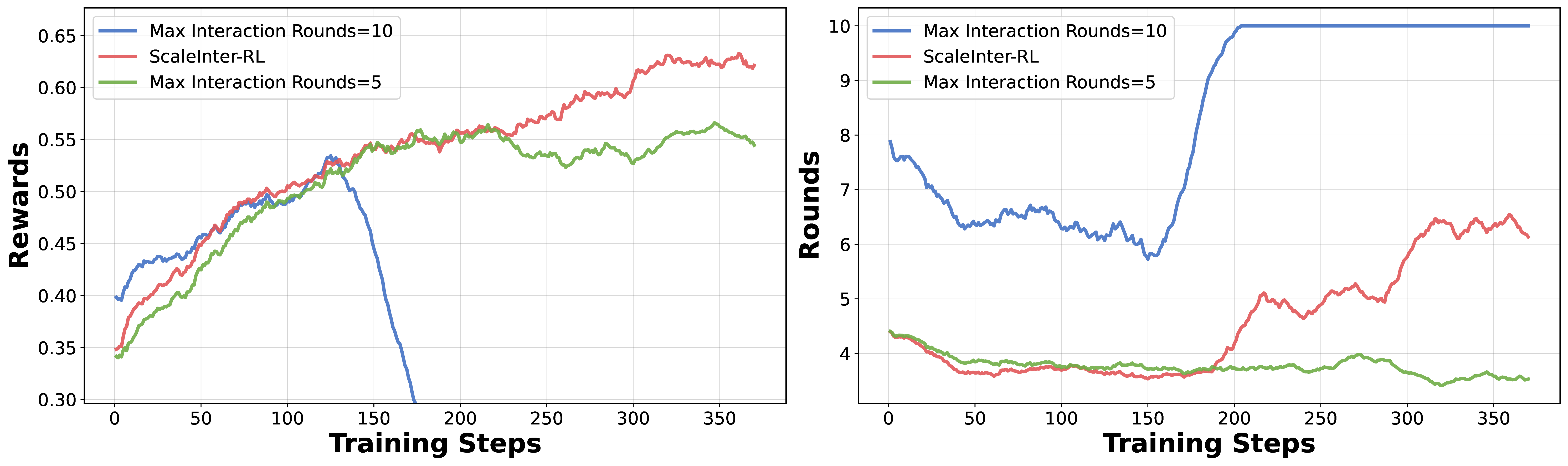
Developing autonomous LLM agents capable of making a series of intelligent decisions to solve complex, real-world tasks is a fast-evolving frontier. Like human cognitive development, agents are expected to acquire knowledge and skills through exploration and interaction with the environment. Despite advances, the community still lacks a unified, interactive reinforcement learning (RL) framework that can effectively train such agents from scratch—without relying on supervised fine-tuning (SFT)—across diverse and realistic environments. To bridge this gap, we introduce AgentGym-RL, a new framework to train LLM agents for multi-turn interactive decision-making through RL. The framework features a modular and decoupled architecture, ensuring high flexibility and extensibility. It encompasses a wide variety of real-world scenarios, and supports mainstream RL algorithms. Furthermore, we propose ScalingInter-RL, a training approach designed for exploration-exploitation balance and stable RL optimization. In early stages, it emphasizes exploitation by restricting the number of interaction, and gradually shifts towards exploration with larger horizons to encourage diverse problem-solving strategies. In this way, the agent develops more diverse behaviors and is less prone to collapse under long horizons. We perform extensive experiments to validate the stability and effectiveness of both the AgentGym-RL framework and ScalingInter-RL approach. Our agents match or surpass commercial models on 27 tasks across diverse environments. We offer key insights and will open-source complete AgentGym-RL framework—including code and datasets—to empower the research community in developing the next generation of intelligent agents.
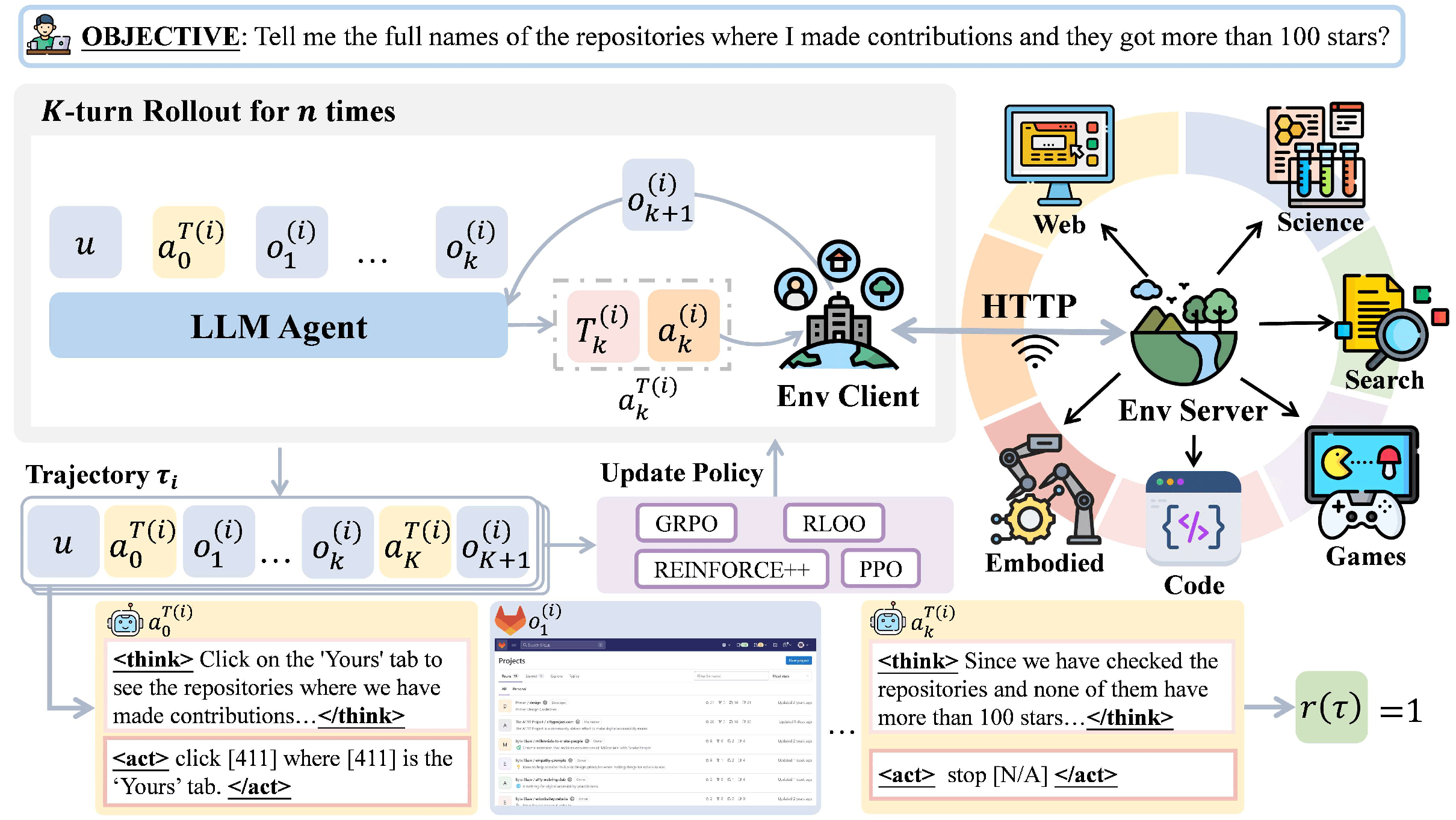
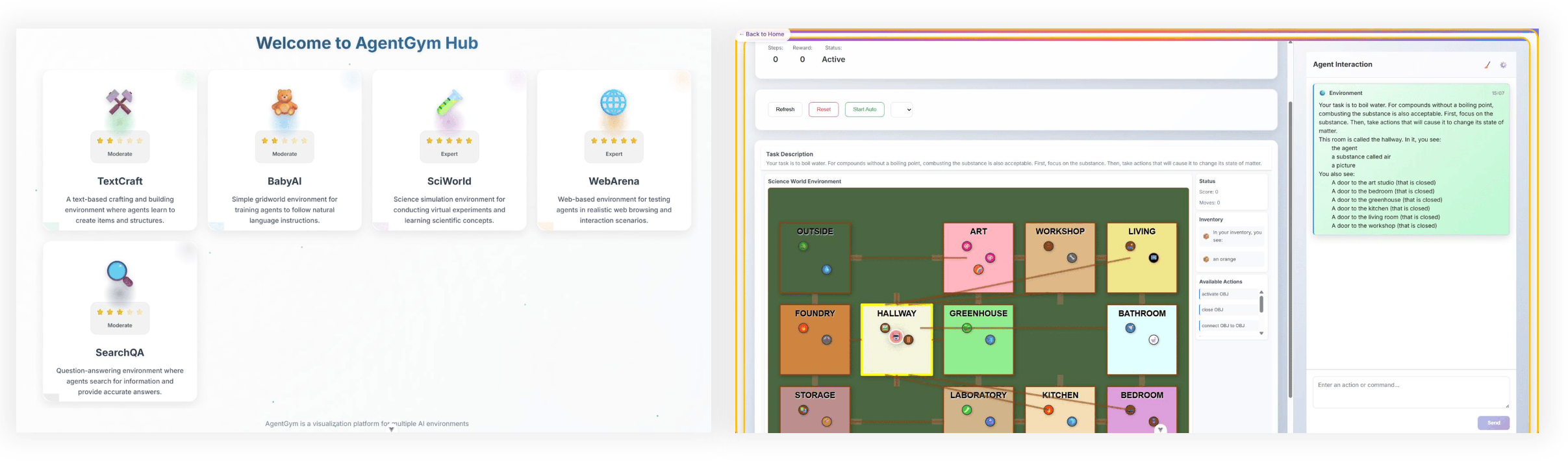
Figure 1: Overview of the AgentGym-RL framework. It features a decoupled, flexible, and extensible architecture, comprising three primary modules—the environment, the agent, and the training module. It supports diverse scenarios, environments, and algorithms.